Single or Monolith Serverless Functions - What should you choose?
Categories:
The term Software Engineering first appeared in the 1960s and today we have close to 27 million software developers across the globe. With our lives surrounded by apps, the need for quality software is growing. Afterall, better the code, better the app. Microservices and serverless are helping make applications more scalable and faster along with making their deployments easier.
However, there’s one question that most developers have today is whether to use single or monolith serverless functions in their applications. In this post, I will try to help answer that.
The Basics
There are a variety of software design principles that enable developers to write better code. One of the popular principles is SOLID. It’s a mnemonic acronym for: Single Responsibility Principle,Open Closed Principle, Liskov Substitution Principle , Interface Segregation Principle and Dependency Inversion Principle.
Design principles like these are not limited to any specific domain or technology. Whether you are writing a low level code that would be etched on a chip or a serverless function that would be running on the cloud. The decision of applying any of these principles depend on the developer and the use case, however following them will only make the code better and optimized.
While all of them are equally important, that one that is of interest to us in this blog post is the single responsibility principle - each function must have only one specific operation that it performs This infact forms the basis of microservices and serverless.
With serverless functions becoming mainstream today, many developers have a question whether to use single or monolith serverless functions for their application? Before we dive into the answer, let’s understand what we mean by single and monolith serverless functions.

Single vs Monolith Serverless Functions
A single serverless function is responsible for only one function in your application. For example and for simplicity, let us assume that you are developing a calculator. In that case, you will have four different functions - add, subtract, multiply and divide - which would be 4 different serverless functions with individual files. So you’ll have a main function that would interact with the user the other functions based on the input.
In case of a monolith serverless function approach, there is just one serverless function that has all the sub functions in it. There’s a logic within the function to call the other sub functions based on the request. In this case you’ll have a single serverless function with add, subtract, divide and multiply functions. The client facing application will call this function which will return the output after processing.
Sample application
To understand the single and monolith serverless functions, we will build a simple Inventory Status Check application developed using Python and Fission functions. The application provides the user with a web UI from where the user can enquire about the inventory status of a product. The application will return the stock amount. If the stock is less than a certain amount, it will show a reorder form that will allow the user to place an order for more stock for that product. Once placed successfully, the app will show a tentative delivery date for the new stock.
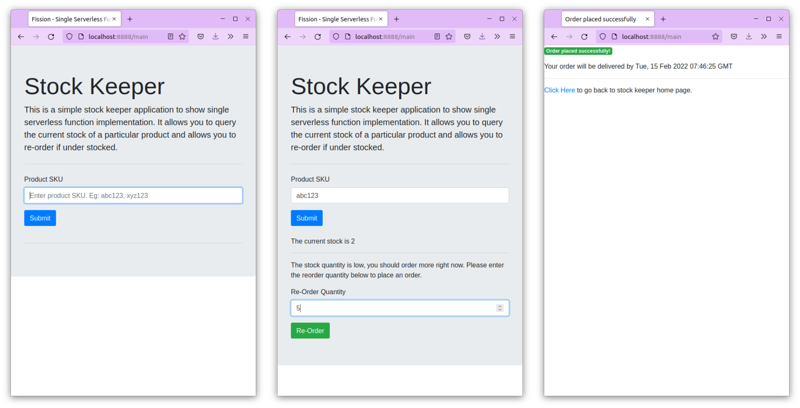
Sample Stock Keeper application
You can refer to the entire code on this application in our Fission GitHub samples repo
Note: For simplicity, the app returns a random number for the stock. For placing the order too, it returns a random date. For real world implementations, you can have the function connect to a database and get the current stock for a product. You can have another function to actually place an order to a 3rd party service.
Single Purpose function
The single purpose function has different functions for each task. It has the following 3 fission functions.
- app.py - the main function with the UI
- getstock.py - function to return the stock count
- reorder.py - function to return the delivery date
The user launches the application and enters a product code. abc123 or xyz123. It internally calls getstock fission function that returns the state of current stock. If the returned stock is less than 5, the user will see another form or reorder. The user will enter the reorder quantity which will be passed to the reorder fission function that will return the estimated delivery date.
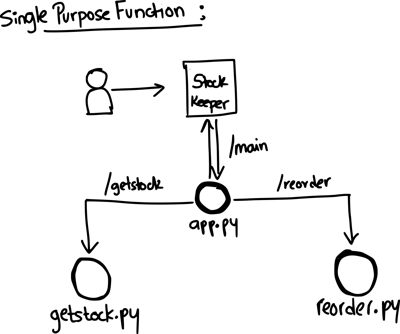
Single purpose fission function
Monolith Function
The monolith function as the name suggests consists of a single fission function that has all the functions within. The app.py in this case has the getstock and reorder functions. In terms of the function, it functions exactly like the single purpose function and the user doesn’t notice any difference.
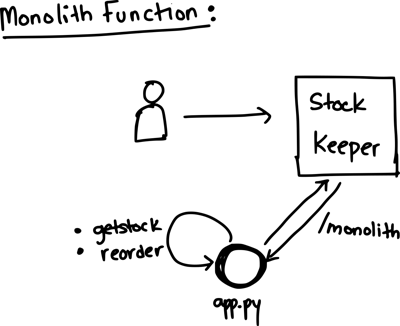
Monolith fission function
So you might ask, What’s the difference between Single or Monolith Serverless functions? Well each of the implementations has its own pros and cons that we will discuss in the next section.
Pros and Cons of both approaches
Single Purpose Serverless Function
This is the vanilla (& the purest) form of serveless design principles. Each function is a separate function with its own file. It comes with a suite of pros and cons outlined as below:
Pros:
- Each function responsible only for one function
- Easier debugging and monitoring - you know exactly which function caused an error
- Modifying application is easier as only one function is touched
Cons:
- As the application grows, maintaining can be tough as the number of functions can be too much
- Security can be a concern with so many functions as the developer needs to ensure that each function has adequate measures in place
- Makes sense if you have a true event driven application
Monolith Serverless Function
You can have a single fission function with a framework that can take requests and pass it on to other functions within the same file.
Pros:
- Reduced system complexity
- Familiarity of the architecture as true serverless is relatively newers for many devs
- Simple development and deployment
Cons:
- Large codebase, tougher to manage in the long run
- Not scale friendly
- Complex upgrades as entire application need to be redeployed
Having gone through the pros and cons of both Single purpose serverless function and monolith serverless functions, which ones makes better sense to use? Both of them are suited for different setups but if you’re looking to create a truly serverless application that’s agile and easy to maintain, a single purpose function is the way to go. They are easy to monitor and debug and also provide better cold start performance.
Conclusion
The application we’ve showcased here shows you how you can actually use fission serverless functions. While none of these design patterns are wrong, it makes much more sense to use a single purpose serverless function to truly leverage the power of serverless. So go ahead and create your own serverless application using Fission and let us know how you went about it. If you’re facing any issues, feel free to join our Fission Slack channel or tweet to us on Twitter @Fissionio