Event Driven Scaling Fission Function Using KEDA
Categories:
Introduction
Events and integrations with event sources such as message queues are an important part of running functions. Fission had the MQ integration for invoking functions and this integration was available for Kafka, NATS, and Azure Queue Storage. This integration had a few limitations:
- For every new integration you want to enable - there was one pod running for enabling the integration
- Autoscaling of the trigger handler was not available.
- Lastly - one Fission installation could connect to and handle only one instance of a MQ. So for example you could only connect to one Kafka instance in a given Fission installation.
When we decided to build out these features we came across KEDA project and it solved most of the limitations which Fission had in the event integration area. Let’s dive into how it works!
Architecture
Let’s first understand how the whole thing works. We won’t explain Keda in detail but you can take a look at Keda documentation for details.
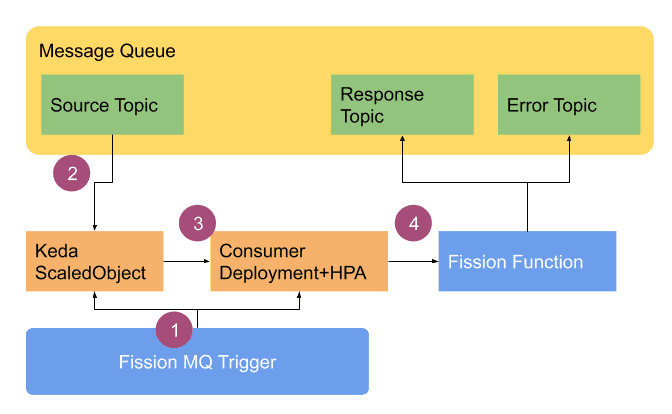
- The user creates a trigger - for Keda based integration you have to specify the “mqtkind=keda” and add all relevant parameters. These parameters are different for each message queue and hence are encapsulated in a metadata field and follow a key-value format. As soon as you create the MQ Trigger, Fission creates a ScaledObject and a consumer deployment object which is referenced by ScaledObject. The ScaledObject is a Keda’s way of encapsulating the consumer deployment and all relevant information for connecting to an event source! Keda goes ahead and creates a HPA for the deployment and scales down the deployment to zero.
- As the message arrives in the event source - the Keda will scale the HPA and deployment from 0 - to 1 for consuming messages. As more messages arrive the deployment is scaled beyond 1 automatically too.
- The deployment is like an connector which consumes messages from the source and then calls a function.
- The function consumes the message and returns the response to deployment pods, which puts the response in response topic and errors in error topic as may be applicable.
Tutorial
The rest of the post will walk through a step by step guide for using the new message queue trigger.
Setup
Prerequisite
- A Kubernetes cluster with the latest version of Fission
- The latest version of Fission-CLI on the local machine
Setup KEDA
We will be deploying KEDA using Helm 3. For more installation options, checkout deploying KEDA.
- Add Helm repo
$ helm repo add kedacore https://kedacore.github.io/charts
- Update Helm repo
$ helm repo update
- Install KEDA Helm chart
$ kubectl create namespace keda
$ helm install keda kedacore/keda --namespace keda
Setup Apache Kafka
There are various ways of using Kafka in the Kubernetes cluster. Here, we are going to use Strimzi, it simplifies the process of running Apache Kafka in a Kubernetes cluster. Follow the installation steps mentioned here and create a Kafka cluster.
Preparation for creating Message Queue Trigger
Since we are done with the setup, now we will need following to create message queue trigger:
- Three Kafka topics
- Producer function
- Consumer function
Creating Kafka Topics
Now, create three Kafka topics as mentioned below, replace namespace and cluster with yours.
- Kafka topic for function invocation
cat << EOF | kubectl create -n my-kafka-project -f -
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaTopic
metadata:
name: request-topic
labels:
strimzi.io/cluster: "my-cluster"
spec:
partitions: 3
replicas: 2
EOF
- Kafka topic for function response
cat << EOF | kubectl create -n my-kafka-project -f -
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaTopic
metadata:
name: response-topic
labels:
strimzi.io/cluster: "my-cluster"
spec:
partitions: 3
replicas: 2
EOF
- Kafka topic for error response
cat << EOF | kubectl create -n my-kafka-project -f -
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaTopic
metadata:
name: error-topic
labels:
strimzi.io/cluster: "my-cluster"
spec:
partitions: 3
replicas: 2
EOF
Creating Producer Function
The producer function is a Go program that creates one thousand messages with the timestamp and drops into a topic input. For brevity, all values have been hardcoded in the code itself. Save the following code as producer.go
package main
import (
"fmt"
"net/http"
"time"
sarama "github.com/Shopify/sarama"
)
// Handler posts a message to Kafka Topic
func Handler(w http.ResponseWriter, r *http.Request) {
brokers := []string{"my-cluster-kafka-brokers.my-kafka-project.svc:9092"}
producerConfig := sarama.NewConfig()
producerConfig.Producer.RequiredAcks = sarama.WaitForAll
producerConfig.Producer.Retry.Max = 100
producerConfig.Producer.Retry.Backoff = 100
producerConfig.Producer.Return.Successes = true
producerConfig.Version = sarama.V1_0_0_0
producer, err := sarama.NewSyncProducer(brokers, producerConfig)
fmt.Println("Created a new producer ", producer)
if err != nil {
panic(err)
}
for msg := 1; msg <= 1000; msg++ {
ts := time.Now().Format(time.RFC3339)
message := fmt.Sprintf("{\"message_number\": %d, \"time_stamp\": \"%s\"}", msg, ts)
_, _, err = producer.SendMessage(&sarama.ProducerMessage{
Topic: "request-topic",
Value: sarama.StringEncoder(message),
})
if err != nil {
w.Write([]byte(fmt.Sprintf("Failed to publish message to topic %s: %v", "request-topic", err)))
return
}
}
w.Write([]byte("Successfully sent to request-topic"))
}
go.mod
module gitub.com/therahulbhati/scalingfissionfunction
go 1.15
require github.com/Shopify/sarama v1.29.0
Let’s create the environment and function
$ fission environment create --name go --image ghcr.io/fission/go-env --builder ghcr.io/fission/go-builder
$ fission fn create --name producer --env go --src producer.go --src go.mod --entrypoint Handler
Creating Consumer Function
The consumer function is a Node Js program. Save the following code with consumer.js
module.exports = async function (context) {
console.log(context.request.body);
let obj = context.request.body;
return {
status: 200,
body: "Consumer Response "+ JSON.stringify(obj)
};
}
Let’s create the environment and function
$ fission env create --name nodeenv --image ghcr.io/fission/node-env
$ fission fn create --name consumer --env nodeenv --code consumer.js
Creating Message Queue Trigger
$ fission mqt create --name kafkatest --function consumer --mqtype kafka --mqtkind keda --topic request-topic --resptopic response-topic --errortopic error-topic --maxretries 3 --metadata bootstrapServers=my-cluster-kafka-brokers.my-kafka-project.svc:9092 --metadata consumerGroup=my-group --metadata topic=request-topic --cooldownperiod=30 --pollinginterval=5
To take leverage advantage of KEDA scaling, one must set --mqtkind keda.
Following is the description of parameter used in creating the message queue trigger:
- name: Name of the message queue trigger
- function: Fission function to be invoked
- mqtype: Message queue type
- topic: Message queue topic the trigger listens on
- mqtkind: Kind of Message Queue Trigger
- resptopic: Topic that the function response is sent on
- errortopic: Topic that the function error messages are sent to
- maxretries: Maximum number of times the function will be retried upon failure
- pollinginterval: Interval to check the message source for up/down scaling operation of consumers
- cooldownperiod: The period to wait after the last trigger reported active before scaling the consumer back to 0
- metadata: Metadata needed for connecting to source system in format: –metadata key1=value1 –metadata key2=value2
Everything in Action
Open one terminal and execute the following to keep watch on pods
$ kubectl get pods -w
Let’s subscribe to our response-topic to see the response return by consumer function invocations. Open another terminal and execute the following:
$ kubectl run kafka-consumer -ti --image=strimzi/kafka:latest-kafka-2.5.0 --rm=true --restart=Never -- bin/kafka-console-consumer.sh --bootstrap-server my-cluster-kafka-brokers.my-kafka-project.svc:9092 --topic response-topic
Since everything is in place, let’s invoke our producer function in another terminal
$ fission fn test --name producer
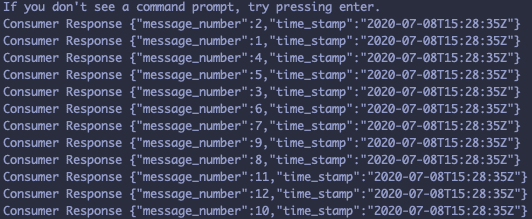
Viola! Now you can see eventually three new pods are being created in the first terminal and response of the consumer function in the second terminal.
You would probably have an output like this in the first terminal

And output like this in the second terminal
What next?
We have developed the Keda Integration and Kafka connector so far and we soon will be adding connectors for RabbitMQ, NATS too. We would love to see more connectors being contributed by the community as there are many integrations that Keda supports!
Here is the guide to Contributing to Fission.
Fission issue link: https://github.com/fission/fission/issues/1663

Authors:
- Rahul Bhati | Fission Contributor | Product Engineer - InfraCloud Technologies