Getting Started: Composing Serverless Functions with Fission Workflows (Part 2)
Categories:
This is the second half of a 2-part introduction to Fission Workflows.
In part One of this series, we talked about the concepts around Fission Workflows, how to create them, as well as a few demos of use cases in which you might use them.
So we’ve gone over what workflows are, along with when, and how to execute them. In this blog post we’ll dive deeper, breaking down each component that makes up the fabric of workflows, and what make workflows so efficient.
Getting Right into It: Inside Workflows
Workflows is designed to be fault-tolerant, high performance, and easy to deploy and operate on Kubernetes.
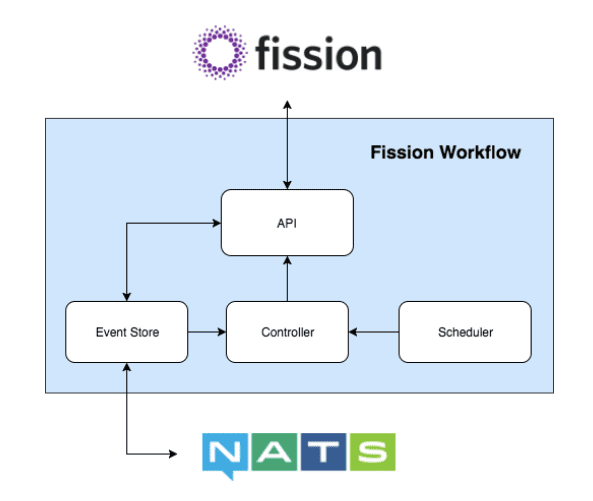
API
The API is the central component of the Fission Workflow system. It is responsible for exposing all actionable aspects of the system. The API is the only component that deals with appending events to the event stores.
Event Store
Actions taken by the API result in most cases in events that update the state of a workflow, workflow invocation or function invocation. The event store is an append-only database or data store that ensures persistent storage of the events.
NATS
Currently, the message system NATS Streaming is used as the underlying event store, as it is fast, offers PubSub functionality, allows for persistence and replays. The interface for the event store is minimal, consisting of APPEND, GET, LIST, WATCH, allowing for easy integration with other data stores if needed.
Controller
The controller is the ’engine’ in the workflow engine. It keeps track of current invocations, queries the scheduler, and executes the instructions of the scheduler for these invocations.
Scheduler
Where the controller is the heart of the workflow system, the scheduler is the brains. When the controller invokes the scheduler for a specific invocation, the scheduler evaluates the current state of invocation. Based on this data and potentially other data sources, such as historical data, it creates a scheduling plan. This scheduling plan contains actions that need to be taken by the controller, such as (re)invoking a function or aborting the workflow invocation all together. The scheduler is completely stateless, so the controller can at any time request a (re)evaluation if needed.
Fission
The workflow engine uses Fission as the underlying ‘function execution layer’. Using the Fission Proxy, Fission is able to treat the workflows as just another Fission function, and treat the workflow engine as just another environment.
Walking Through the Lifecycle of a Workflow
The user defines a workflow definition in the YAML data format.
The user uploads the workflow to the Fission function storage, like any other function.
The workflow is parsed and validated to the internal format.
The workflow is triggered, for example by an user sending a request to a specific HTTP endpoint.
Fission specializes the workflow engine with the relevant workflow, just like any other environment.
After specializing, the request creates a workflow invocation in the workflow engine.
The controller picks up the new workflow invocation, and requests a execution plan from the scheduler.
The scheduler determines the optimal planning for the workflow invocation, and returns it to the controller.
The controller executes the execution plan of the workflow invocation, performing (Fission) function calls.
The results of these function calls arrive as events into the event queue, which again trigger the controller to evaluate the invocation.
This process continues until all tasks have succeeded or an unhandled error has occurred.
In case of a synchronous invocation, the resulting output of the workflow invocation is returned to the user.
Performance
Why it’s fast
A rather important characteristic of Fission Workflows is the requirement to be fast. This uncommon property in traditional workflow engines, which often are focused purely on throughput rather than latency of individual invocations. With “serverless workflows” the latency becomes one of the most important metrics.
At its core the workflow engine makes use of the high-performance NATS streaming message queue to store the events. Throughout the system a reactive paradigm is used to ensure fast handling of incoming events.
Traditional workflow engines create extensive executions plans, attempting to optimally consume the available resources. In contrast, with serverless workflows, it is more important for the scheduler to come to a decision fast. There is a trade-off between being fast and being correct. The scheduler in the Fission Workflows system focuses on speed by limiting its scheduling to only schedule in the short term. With the highly dynamic and on-demand nature of serverless computing, creating long term plans does not weigh against the scheduling effort.
Finally, Fission Workflows has a modular structure. The system can be striped to be solely consist of the bare-minimum components needed to manage the workflows.
Why it’s scalable
From a distributed systems perspectives FaaS is an interesting notion, as the the the serverless functions have useful properties such as being short-lived, stateless and on-demand. This allows the infrastructure to have far more control over the lifecycle of the functions. For workflows of these functions similar properties hold.
Why it’s fault-tolerant
A main benefit over other ways to compose functions, such as using a message queue or using a coordinating function, is that workflow engines are capable of providing better fault-tolerance. This is enabled by the explicit dependency structure and the centralized orchestration of the workflow.
Instead of storing the state and having to deal with keeping the state up to date and safe, we store the operations instead. Every event related to the workflows is stored in the event store. The state is created by applying the events to some materialized view. This also allows the workflow engine to reconstruct its state from the stored events. This allows the workflow engines to go down or temporary unavailable without losing state.
Although Fission Workflows is mainly event-driven to keep the latency low, there are always cases in which events are not propagated through the system. This can have various causes, such as network unavailability, resource constraints, or long-tail latencies. For this reason the workflow engine at its core is a control system. It utilizes a control loop, in which it periodically checks the various caches and the event store for any untracked or unfinished workflow invocations.
How it’s extensible
In contrast to other vendor-specific workflow engines, Fission Workflows has been designed from the ground up to be open for extensibility. The main aim of the system is to avoid any form of hard-coded functionality or differences in functionality between the system and the users.
Instead of offering a limited set of control flow structs Fission Workflows exposes the concept of dynamic tasks; tasks that return a task themselves. This concept allows users to treat tasks as data. This opens up a wide range of possibilities for the user to alter the static control flow in the workflow invocation. Although Fission Workflows offers some useful dynamic tasks, such as if-conditions, switches and for-loops, there is nothing special about these tasks. Users can use the same API to define their own dynamic tasks.
In most workflow systems the predefined control flow structs have a privileged execution environment by executing those within the workflow engine. User-defined functions do not have that same privilege and can therefore never attain the same characteristics, like performance, as the privileged functions. In Fission Workflows there is also the concept of an internal execution environment, allowing functions to be executed within the workflow engine. However, this environment is just like any other function execution runtime, allowing users to create their own internal functions.
Also, the query language, a JavaScript interpreter, is like the internal functions, easy to extend. Here too, there are some predefined query functions, but they make use of the public API as any other function.
Related Work
Fission Workflows is the only open source serverless workflow framework on Kubernetes. However, the concept of workflows is not new at all, and has precedent in scientific data processing, data analytics pipelines, and infrastructure/devops automation.
AWS Step Functions and Azure Logic Apps are most similar in terms of the intended workloads and use cases. However, unlike Fission Workflows, these serverless workflow engines are vendor-specific, closed source, and limited in extensibility.
Data processing workflow engines, such as Luigi and Apache Airflow, have been popular in their field and are relatively mature. The focus of these workflow engines is on efficiently processing of batches of data efficiently, with little regard for latency. Nor do these systems make use of the cloud native paradigm.
From the academic world, Pegasus and Pywren, focus on huge scientific workflows. These types of workflows, and engines, typically run infrequently, which prevents any historical-based optimizations.
Roadmap
Here are a few additional features that we’re working on to enhance workflows!
Programming Workflows: A Python library that allows users to generate workflows by just writing code and feeding it to a parser.
GUI/Visualization: A visualization tool that allows users to see the status of the workflows and see the execution visually of a workflow invocation.
To learn more about Fission Workflows and other function composition styles, you can check us out at KubeConEU this year in Copenhagen, Denmark! Come attend our talk “Function Composition in a Serverless World” and visit us at the Platform9 booth! :)
You can also see us at Velocity in San Jose, CA!
Don’t Forget to Join our Community!
Authors:
Timirah James | Fission Developer Advocate, Platform9 Systems | Tweet the Author
Erwin Van Eyk | Software Engineer Intern, Platform9 Systems | Tweet the Author