Function Composition in a Serverless World [Video]
Categories:
Earlier this month, Software Engineer Erwin van Eyk and Developer Advocate Timirah James gave an awesome talk on function composition at KubeCon EU in Copenhagen, Denmark. The talk covered 5 serverless function composition styles and the significance of function composition when deploying serverless functions.
You can view and download the slides here, or you can check out the video below.
What’s FaaS?
FaaS is FaaS of course is functions as a service and FaaS frameworks allow developers to deploy individual parts of an application on an as-needed basis.
So there are a couple of benefits here:
It’s super developer friendly and the way that it strips the obligation of having to manage or maintain servers
It also has a pretty great billing model as you only pay for the resources that you actually consume
When you’re using FaaS frameworks scaling is simplified
What is Function Composition?
Function composition refers to the concept of creating what we like to call “super function combinations”. Simply put: it’s taking smaller functions and using them to create bigger more complex functions in efforts to gain more efficient and sophisticated functionality.
The way you compose functions can play a key role in how your functions are deployed in terms of latency, resource usage (and ultimately costs), as well as the responsibility that you as a developer may have as it pertains to the success or the failure of your functions overall.
Example Use Case
Here’s our example use case:
We have an application that sends a photo to a third-party image recognition API and it’s going to grab the first generated tag and convert that text from English to Danish.
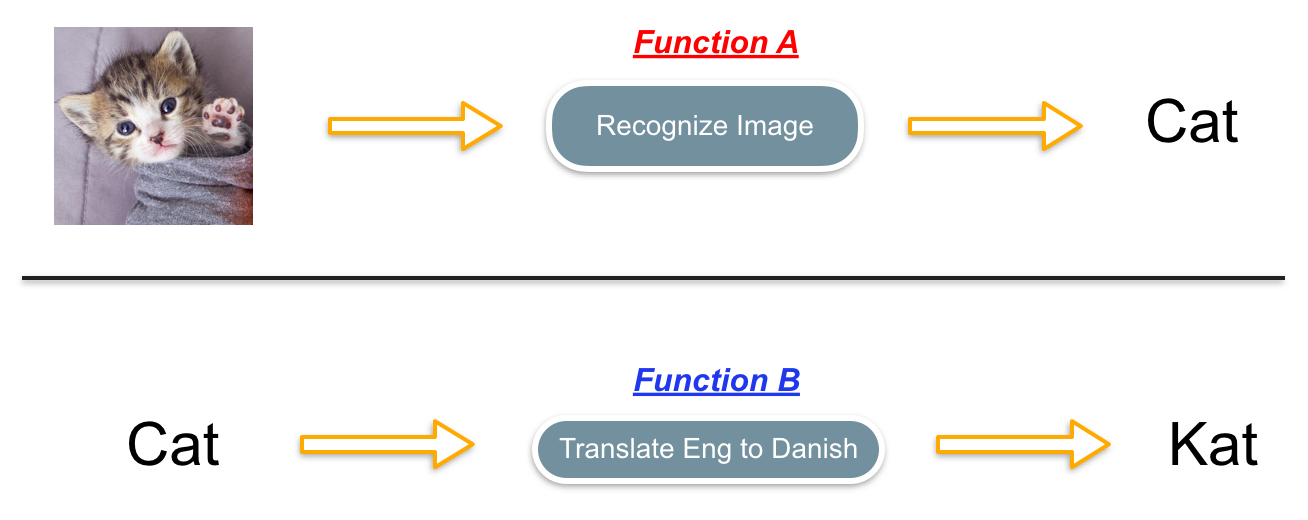
The photo above implies that these are two separate functions. But can we combine both functions into one service? The answer is simple… of course we can!
In the next section, we’ll be going over how we can do just that using different function composition styles and weighing the ideal and not-so-ideal elements of each style.
Manual Compilation
Probably the easiest way to combine functions is to just do it on a source code level. But when you do this using a FaaS framework, that FaaS framework won’t recognize those functions as separate tasks. Instead, they will be viewed as one big function. I’m going to point out why that might be a problem in a bit.
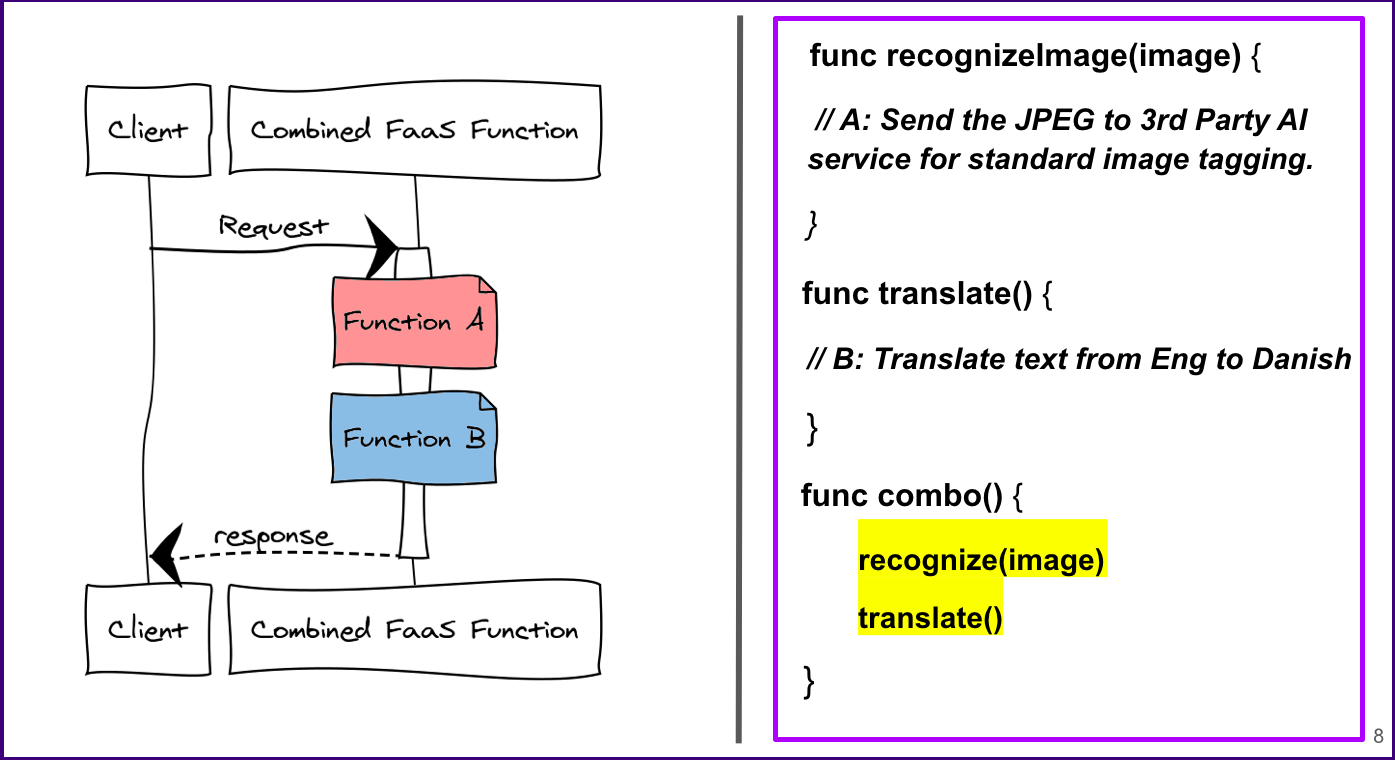
On the right, we have some pseudo code where we have our two functions (Function A + Function B). Then at the very bottom, we have a function which calls both Function A and Function B at once.
Pros
Can be done at a source code level (you actually really don’t need a FaaS framework to do this)
There’s no serialization overhead
Cons
The bigger the function the slower the load time may be
Can’t scale functions independently
Now let’s break down that last con: the inability to be able to scale the functions independently. This con can be pretty wasteful and perhaps costly.
Even though we’ve merged these functions together, they are still two individual tasks. So each function within uses their own amount of resources, their own amount of memory, their own amount of CPU, etc. So when you’re thinking about a case in which there’s a request being made that only requires one of these functions or a portion of the functionality, being that the FaaS framework recognizes it both of these functions as one, this can potentially cause waste using excess resources. In this case, you’d be defeating the purpose of the main benefit of using FaaS – which is that you’re only supposed to be paying for the resources that are needed and actually consumed.
Direct (Chaining)
This composition style is pretty common. Chaining is where the user combines their functions in the form of… well… a chain. The functions are nested within each other, but each task is a separate FaaS function, and each function is fully aware of the next.
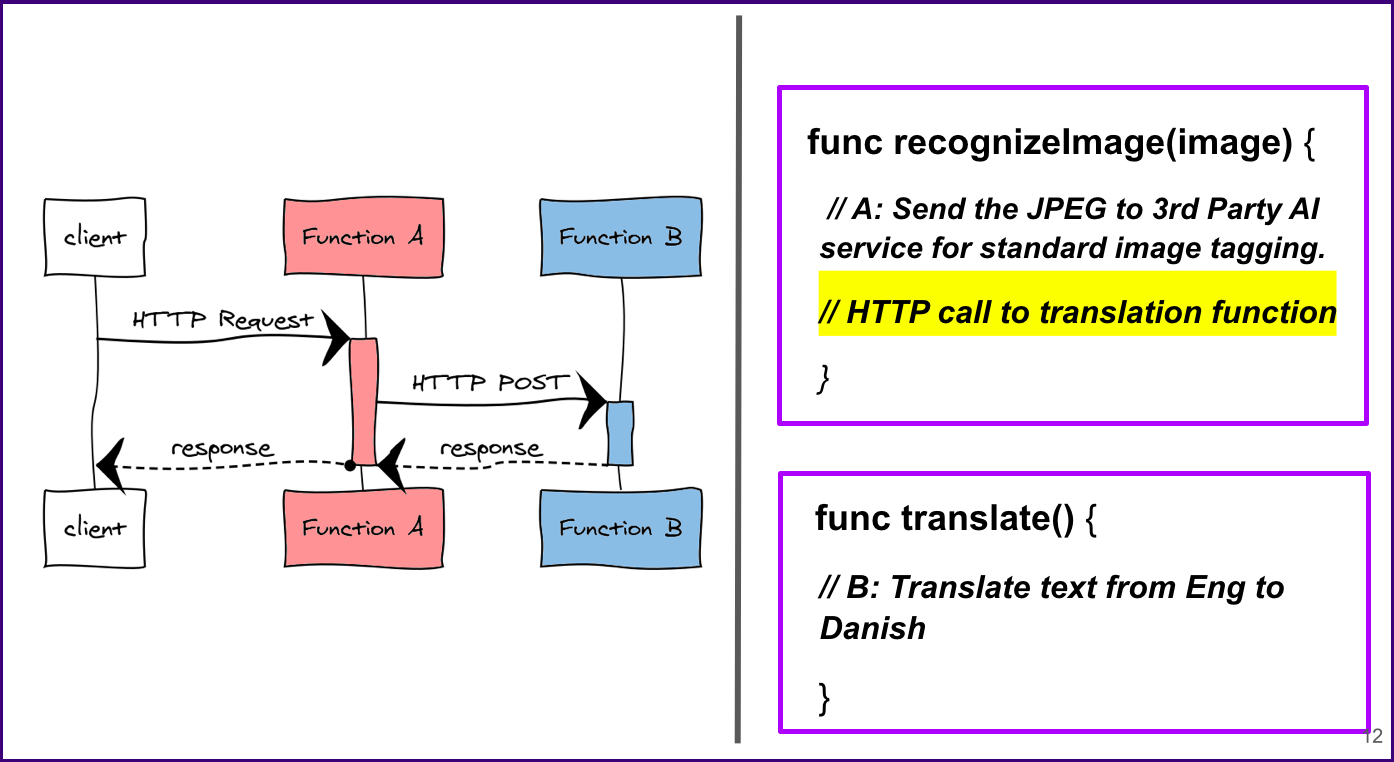
Here we have our code, and as you can see they’re separate and there’s an HTTP call being made from our first function (Function A) to the next function. Function is making that HTTP request to Function B. Function A waits for the response from Function B before it ends and sends it’s response back to the client.
Let’s break down and dissect some of the pros and cons here.
Pros
Once again you don’t actually need any external components to execute this style, and there’s no serialization overhead just as with manual compilation.
Cons
The cons of chaining functions can also be costly.
With each function waiting for the next, each function will have some sort of dormancy, the added idle time could be wasteful in terms of resource usage and therefore costs.
Another con involves what we call “operational complexity”, which means that the user becomes responsible for things like handling failures, fallbacks, and retries. All of this of falls back on you… which leads me to the next con, which is the pain of having to update an individual function.
If each function is dependent upon the prior and following function, imagine having to make a major update to a single function. It could turn into a big headache, fast!
Coordinating
Coordinating functions is where you create an additional function that essentially acts as a director or a “coordinator”, which has an omniscient role of knowing and executing the full sequence of functions. It manages the full execution flow. This is similar to direct functions except here, the functions are completely unaware of each other.
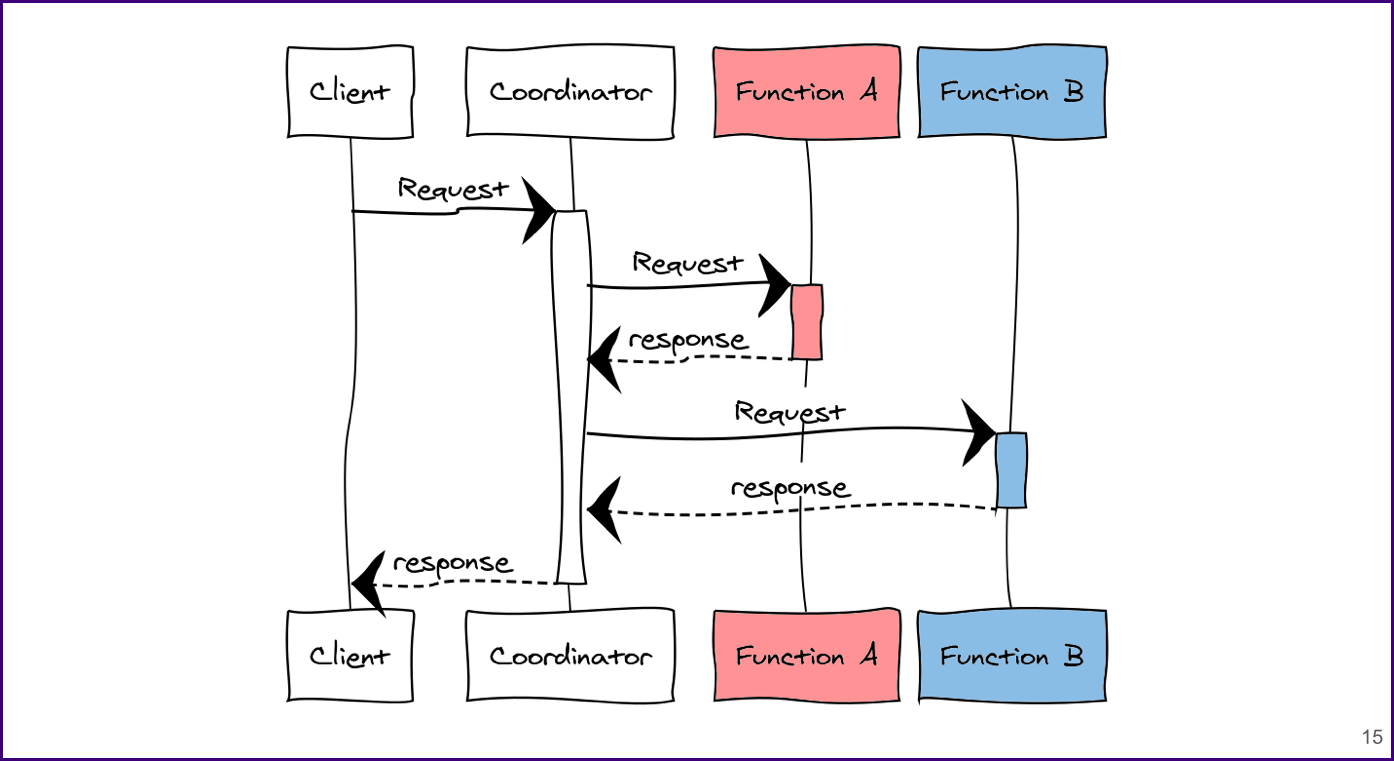
Now we have an additional coordinator function. A request is made to Function A, and once that response comes back, our coordinator function makes another request to Function B. Once the coordinator function receives a response from Function B, it will then send a response back to the client.
Pros
This is great because you don’t need to modify the primitive functions. Coordinator functions also give the user a little bit more control as they’re able to manipulate the control flow.
Cons
So there’s the overhead of having to add the additional function. Also, you’ll have to consider the fact that the coordinator function is the first function to start, and the last to finish. So here in our example we only have two functions, so this might in fact be a suitable approach. But suppose we had 10 functions? Or 12 functions? Or 50? Now it becomes a concern of wasting a lot of resources, time, and memory with just the dormancy of the coordinator function alone.
Now the next two approaches will be a little different from the ones we’ve gone over, as they require some component in infrastructure to use them.
Event-Driven
The event-driven approach is a very common and well understood architecture.
With the event-driven composition style, the idea is here is that you have these functions that are triggered by events, which are embedded in message queues (via brokers like Kafka, NATS, etc.). Each function is tied to a request queue and a response queue. When triggered, a function executes. Once the function ends, it emits an event, which can trigger another function.
With all the other composition styles, we specify the order of our composition explicitly – stating the control flow. Here, we’ve switched our focus from computation to data. So in this case, we basically make this function dependent on data, and by coincidence, these functions will emit the data that the next one needs.
In our example we now have this new component, the message queue, and we set up the functions prior to this to be triggered for specific events.
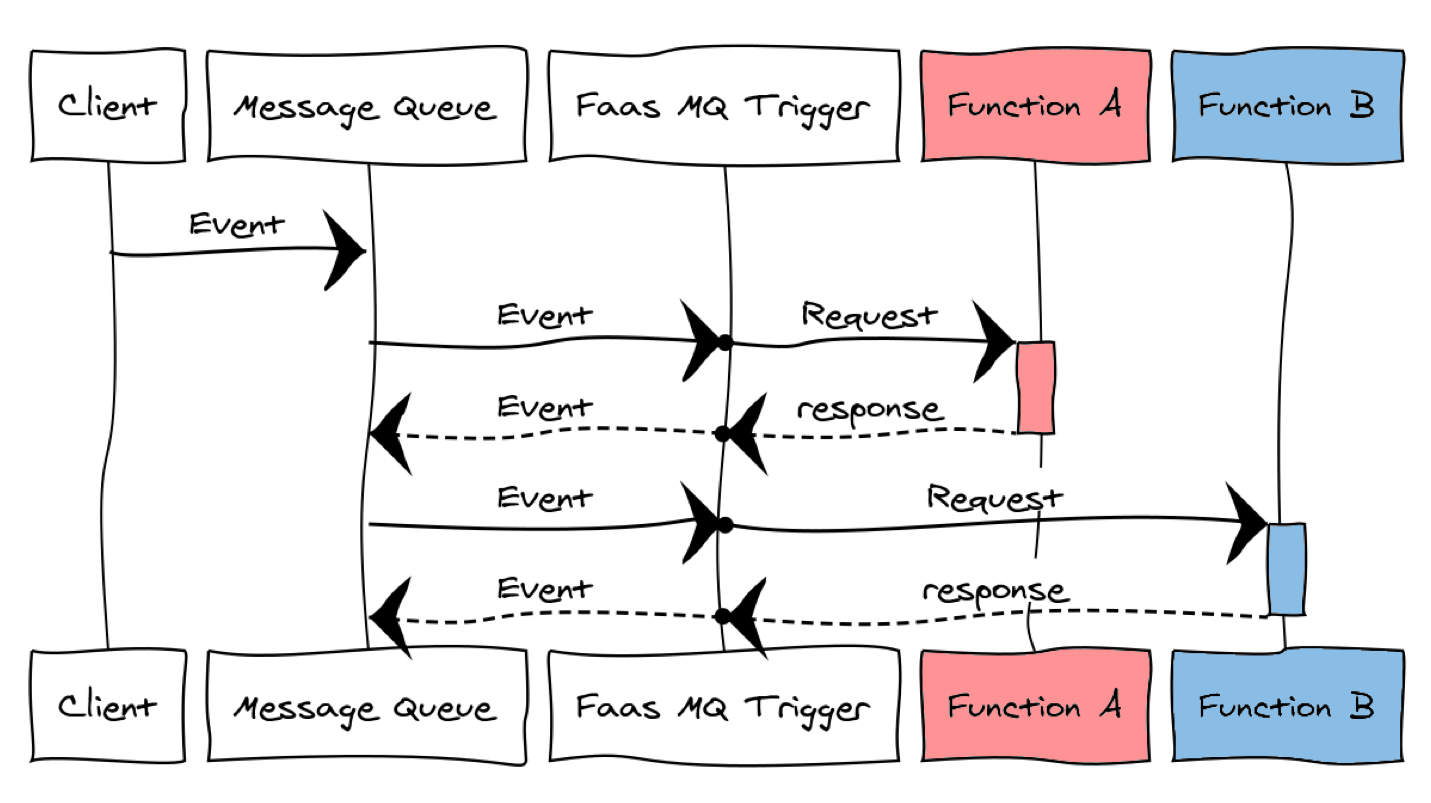
So what’s happening here? The client emits an event, which coincidentally happens to be the event needed to trigger Function A, and once it completes, another event is emitted and triggers another function on the message queue.
So Function A is triggered, it runs and completes, and is published again on the message queue. This event triggers Function B only because it is triggered on that specific function.
Pros
The biggest benefit here is that you really get all the luxuries of message queues. Message queues are very reliable and they save you from having to implement all the retrying logic and the communication logic that’s associated with delivering messages from A to B.
Another good thing is that all the functions are decoupled. They don’t need to have any knowledge of each other whatsoever in order to run.
Cons
Notice I kept emphasizing the word “coincidentally” here? That’s because with this approach, it can literally become a web of implicit dependencies.
Imagine a system in production where you have tens, or hundreds, or even thousands of functions all having these implicit compositions in between them. The structure of these implicit compositions can become difficult to understand, and even dangerous to add or remove functions because they might be used by some another function somewhere else in the system. This can also make it super difficult for function versioning as well.
Workflows
Workflows is a very common notion used in many domains such as DevOps optimization, business processing, and data pipelining.
Workflows is an approach which uses a new runtime framework to execute a visual flowchart of function interactions. Here, a function will only begin to execute once its dependencies are done.
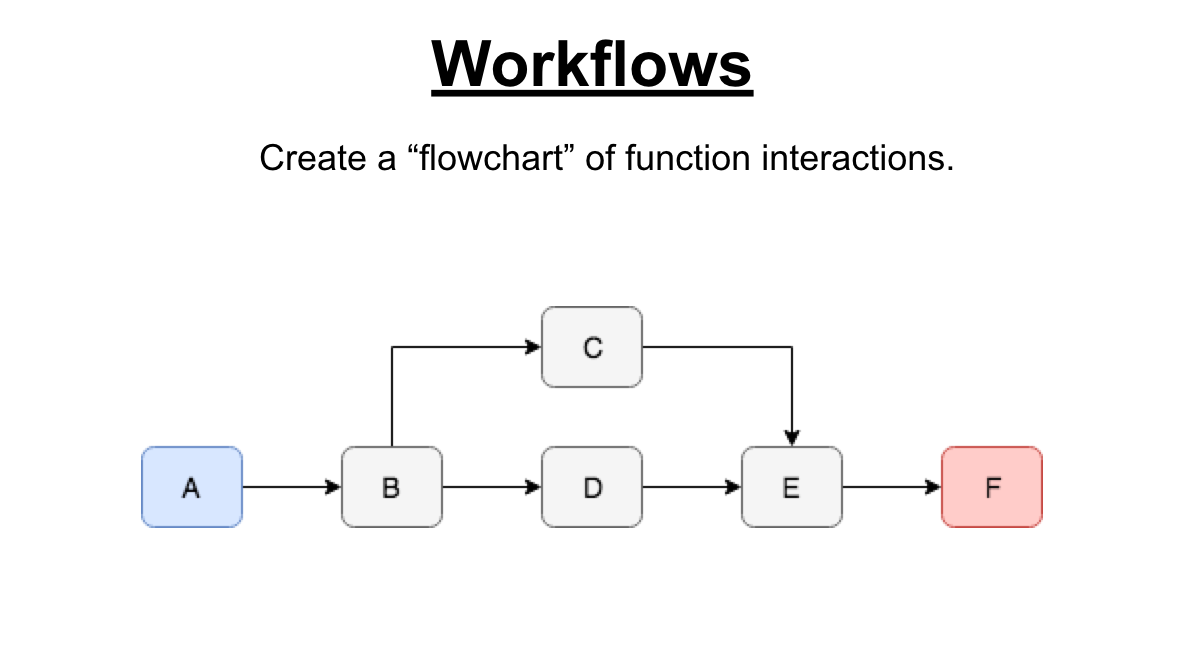
So now, instead of our message queue, we have a workflow engine. Also the client doesn’t communicate directly to the functions, instead it submits a job to the workflow engine. The workflow engine then takes the job and combines it with the workflow definition it has (usually written in YAML) in order to figure out which function to execute and the order it needs to be executed in. So in our example it would be first A, then B.
Pros
The single most important benefit of using workflows is probably the centralization of the logic – from the logging, to the visualization, to the monitoring, retries, etc.
Also the workflow engine has the ability to learn from previous invocations in order to improve performance (pre-booting functions) and prevent cold-starts.
One similarity that workflows have with message queues is that you’re only defining relationships and where the actual data should go. But operations such as making sure the right data goes the right place at the right time, is all handled by the workflow engine itself.
Cons
The main downside to using workflows is that workflow engine add more another layer of complexity. Also, you’d have to use a “workflow-specific” language such as YAML in order to define workflows, which can sometimes be a pain.
Workflows: Diving Deeper with Fission Workflows
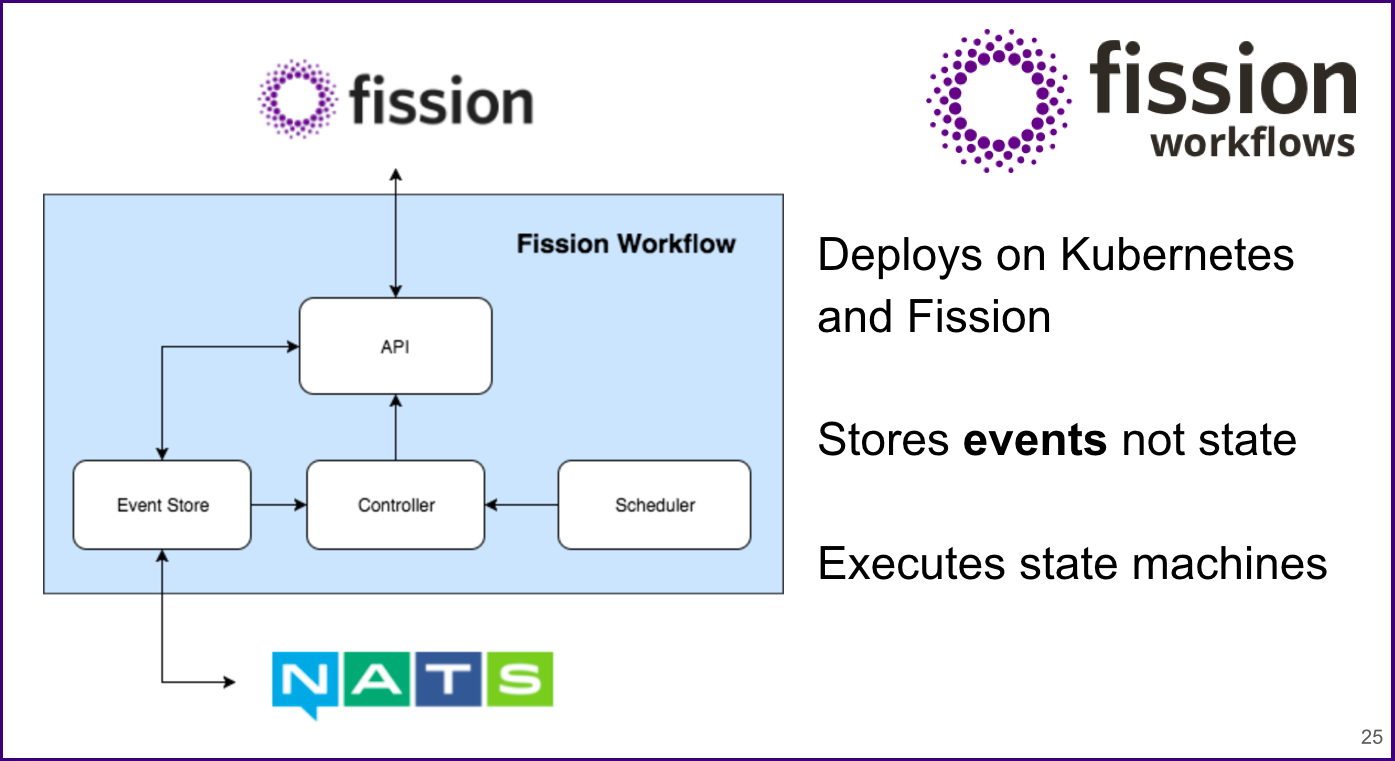
Over the last year, we’ve built and maintained our open source workflow engine, Fission Workflows. Fission Workflows deploys on Kubernetes using Fission as it’s FaaS platform.
Fission Workflows utilizes two main concepts:
Event Sourcing (doesn’t store the state of workflow executions, but rather stores all the events that are related to the workflow executions)
Controlled Base (a controller keeps track of the workflow execution state and decides with the scheduler on which functions to execute next)
Check out some example use cases using Fission Workflows here!
OR
Explore and learn about the inner workings of our workflow engine, Fission Workflows here!
So Which Approach Should YOU Use?..
The simple answer… it depends! All of these serverless function composition styles are super diverse, and depending on the complexity of your applications and of your individual functions, you’ll ultimately have to make the decision on what is worth the given risks and what is not. Most times it may even take multiple composition styles to get the job done just right to cater to your particular use case.
Go ahead and explore and play around with a few composition styles using Fission with this repo!
If you enjoyed this blog post, be sure to catch our talk at Velocity next month in San Jose, CA! :)
And don’t forget to tweet us!! @fissionio
Learn more & Join the Fission Community + Slack Channel here!
Authors:
Timirah James | Fission Developer Advocate, Platform9 Systems | Tweet the Author
Erwin Van Eyk | Software Engineer Intern, Platform9 Systems | Tweet the Author